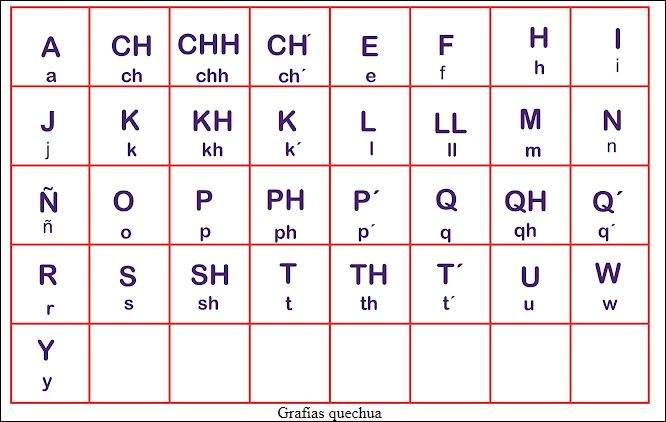
Alfabeto quechua cusqueño consta de 24 letras, incluyendo vocales (a, e, i, o, u) y consonantes (como p, t, k, q, s, ch, sh). Se caracteriza por la ausencia de algunas letras del alfabeto español, como la «b» y la «d», y su pronunciación es fonética, facilitando la lectura.
Alfabeto quechua: letras oficiales
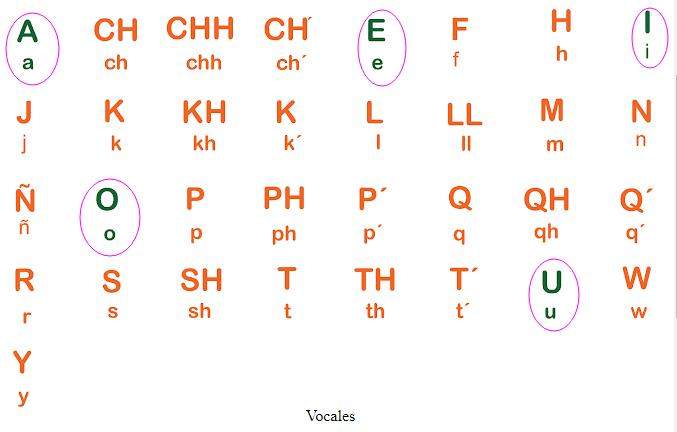
El quechua usa oficialmente 3 vocales: a, i, u.
Aunque en algunas zonas se usan 5 vocales (a, e, i, o, u).3 vocales vs 5 vocales
- 3 vocales (a, i, u): Es el sistema oficial en Perú y el más recomendado. El quechua realmente solo tiene 3 sonidos de vocales.
- 5 vocales (a, e, i, o, u): Se usa mucho en Cusco y zonas tradicionales. Es más fácil para quienes hablan español, pero no es el estándar oficial.
Diferencias regionales
- Perú: Oficialmente 3 vocales.
- Cusco: Prefieren las 5 vocales.
- Bolivia y Ecuador: También usan principalmente 3 vocales, con pequeños cambios según la zona.
OficializaciónEn Perú se oficializó en 1975. Desde 1985 se estableció el uso de solo 3 vocales para preservar la lengua y evitar mezclas con el español.
Alfabeto quechua vocales
El quechua tiene solo 3 vocales: a, i, u.
| Vocal | Pronunciación | Ejemplo |
|---|---|---|
| A | Similar a la “a” del español | allpa (tierra) |
| I | Sonido cerrado, como “i” | inti (sol) |
| U | Sonido posterior, como “u” | urqu (cerro) |
Sistema trivocálicoEl quechua oficial usa el sistema de 3 vocales (trivocálico). Esto significa que solo existen estos tres sonidos de vocales en la lengua.¿Por qué aparecen “e” y “o” en algunos textos?En muchas zonas (sobre todo en Cusco) la gente escribe con 5 vocales (a, e, i, o, u).
Esto pasa porque:
- Cuando la “i” o “u” están cerca de ciertas consonantes (como q, qh, q’), suenan parecidas a “e” y “o”.
- Es más fácil de leer para quienes hablan español.
Recomendación oficial: usar solo a, i, u para escribir correctamente en quechua estándar.
Consonantes del alfabeto quechua
Principales consonantes del quechua
- Consonantes comunes: p, t, k, m, n, s, r, l, y, h
- Sonidos especiales: ch, ll, ñ, q, w
- Sonidos guturales: q, qh, q’ (muy importantes en quechua)
- Aspiradas: ph, th, kh, chh
- Glotalizadas: p’, t’, k’, q’
El quechua tiene muchos sonidos especiales. Aquí tienes el cuadro completo con las consonantes más importantes:
| Letra | Pronunciación | Ejemplo | Significado |
|---|---|---|---|
| Ch | Como «ch» en chico | chakra | campo |
| Ch’ | Glotalizado (corte en la garganta) | ch’aki | sed |
| Chh | Aspirado (con aire) | chhanka | grande |
| K | Como «c» o «k» normal | kantu | orilla |
| K’ | Glotalizado | k’atu | antiguo |
| Kh | Aspirado (gutural) | khasa | hielo |
| Ll | Como «ll» en llama | llapa | todo |
| Ñ | Como «ñ» en niño | ñan | camino |
| P | Como «p» normal | pampa | llanura |
| P’ | Glotalizado | p’ampaku | entierro |
| Ph | Aspirado | phuyu | nube |
| Q | Gutural fuerte (garganta) | qori | oro |
| Q’ | Glotalizado gutural | q’ara | pelado |
| Qh | Aspirado gutural | qhasi | gratis |
| S | Como «s» en sol | sasi | ayuno |
| T | Como «t» normal | tanta | pan / reunión |
| T’ | Glotalizado | t’anta | pan |
| Th | Aspirado | thanta | usado / viejo |
| W | Como «u» corta (water) | wasi | casa |
| Y | Como «y» en yo | yaku | agua |
Pronunciación del alfabeto quechua
El quechua se pronuncia tal como se escribe, pero tiene varios sonidos especiales que no existen en el español.
Diferencias principales con el español
- Se lee exactamente como está escrito (sin letras mudas).
- Solo usa 3 vocales: a, i, u.
- Tiene sonidos guturales (desde la garganta) muy característicos.
Sonidos más importantes
| Letra | Cómo pronunciar | Ejemplo | Significado |
|---|---|---|---|
| Q | Gutural profundo (más atrás que la «k») | qori | oro |
| Qh | Q + mucho aire (aspirado) | qhari | hombre |
| Q’ | Q con corte fuerte en la garganta | q’ara | pellejo |
| K | Como «k» normal, pero más suave | kallpa | fuerza |
| W | Como «u» corta (igual que «water») | wasi | casa |
| Ll | Como «ll» en llama (sonido lateral) | llullu | tierno / bebé |
Consejo práctico:
Los sonidos Q, Qh y Q’ son los más difíciles para los hispanohablantes. Practícalos haciendo un sonido desde el fondo de la garganta, como si estuvieras gargareando suavemente.
Diferencias entre el alfabeto quechua y el español
Alfabeto quechua y el español son muy diferentes, aunque usan casi las mismas letras.
Principales diferencias:
- Sin B, D, G tradicionales
El quechua no usa las letras b, d, g (excepto en palabras prestadas del español).
En su lugar usa p, t, k (sonidos más fuertes y claros). - Solo 3 vocales
Mientras el español tiene 5 vocales (a, e, i, o, u), el quechua oficial solo tiene a, i, u.
Las e y o que aparecen en algunos textos son solo variaciones de pronunciación. - Pronunciación más fonética
En quechua se escribe exactamente como se pronuncia.
No hay letras mudas ni combinaciones raras. Cada letra representa un solo sonido claro.
Resumen de diferencias:
| Aspecto | Español | Quechua |
|---|---|---|
| Vocales | 5 (a e i o u) | 3 (a i u) |
| Letras B, D, G | Muy comunes | Casi no se usan |
| Pronunciación | Irregular | Muy fonética y regular |
| Sonidos especiales | Pocos | Muchos (q, qh, q’, etc.) |
Ejemplos de palabras en quechua por letra
Aquí tienes ejemplos prácticos y útiles de palabras en quechua ordenadas por letra. Perfecto para practicar pronunciación y vocabulario básico:
| Letra | Palabra | Traducción |
|---|---|---|
| A | allpa | tierra |
| Ch | chakra | campo / chacra |
| I | inti | sol |
| K | kusi | alegría / feliz |
| L | lampa | pala |
| Ll | llapa | todo / todos |
| M | mama | madre |
| N | ñan | camino |
| P | pampa | llanura / valle |
| Q | qori | oro |
| Q’ | q’ara | pelado / desnudo |
| R | runa | persona / ser humano |
| S | sara | maíz |
| T | tanta | pan |
| U | urqu | cerro / montaña |
| W | wasi | casa |
| Y | yaku | agua |
Palabras más usadas:
- Munay = amor / querer
- Sumaq = hermoso / bonito
- Apu = señor / montaña sagrada
Tip: Practica leyendo estas palabras en voz alta. Recuerda pronunciar la Q desde la garganta.
¿El quechua tiene 3 o 5 vocales?
Esta es una de las preguntas más comunes y uno de los grandes debates del quechua actual.
Respuesta clara:
El quechua oficialmente tiene 3 vocales: a, i, u.
Sin embargo, muchas personas usan 5 vocales (a, e, i, o, u).
¿Por qué existe este debate?
- Sistema de 3 vocales (trivocálico):
Es el oficial en Perú desde 1985. Se basa en la lingüística real: el quechua solo tiene 3 sonidos vocálicos. Las “e” y “o” son variaciones automáticas según las consonantes cercanas (especialmente la q). - Sistema de 5 vocales (pentavocálico):
Es el más usado en Cusco y zonas tradicionales. La Academia Mayor de la Lengua Quechua defiende este sistema porque refleja mejor cómo habla la gente y es más fácil para quienes hablan español.
Reforma ortográfica
- En 1975 se oficializó el quechua con 5 vocales.
- En 1985 el gobierno peruano cambió a 3 vocales para preservar la estructura original de la lengua y evitar su castellanización.
Variantes regionales
- Cusco y sur: Prefieren 5 vocales.
- Ayacucho, Ancash, Huancayo: Mayormente usan 3 vocales.
- Bolivia y Ecuador: Generalmente usan el sistema de 3 vocales.
Tanto 3 como 5 vocales son aceptados según la región. Para uso oficial, educación o escritura estandarizada se recomienda usar solo 3 vocales (a, i, u).
Recursos relacionados para aprender quechua
Si quieres seguir aprendiendo vocabulario y gramática básica, también puedes explorar estos contenidos relacionados:
Si te interesa un enfoque más avanzado, también puedes leer nuestro análisis computacional del alfabeto quechua, donde estudiamos frecuencias de letras, bigramas y patrones estructurales del sistema ortográfico.
- Palabras en quechua por orden alfabético
- Pronombres personales en quechua
- Preguntas básicas en quechua
- Saludos en quechua
- Palabras en quechua con CH, CHH y CH’
¿Cuál es el alfabeto oficial del quechua?
El alfabeto oficial del quechua en Perú es el establecido en 1985. Utiliza 3 vocales (a, i, u) y un conjunto de consonantes que incluyen sonidos especiales como q, qh, q’, ch, ll, ñ y w.
¿Cuántas vocales tiene el quechua?
Oficialmente tiene 3 vocales (a, i, u). Aunque en Cusco y algunas zonas se usa el sistema de 5 vocales (a, e, i, o, u), el estándar oficial es el trivocálico.
¿Qué letras no existen en quechua?
El quechua no usa las letras b, d, g (salvo en palabras prestadas del español). Tampoco usa c (excepto en “ch”), v, x ni z.
¿Cómo se pronuncia la Q en quechua?
La q se pronuncia con un sonido gutural profundo, desde el fondo de la garganta (más atrás que la “k”). Es uno de los sonidos más característicos del quechua. Ejemplo: qori (oro).
¿El quechua se escribe igual en todas las regiones?
No. Aunque existe un alfabeto oficial, hay diferencias regionales. Cusco prefiere 5 vocales, mientras que otras regiones (Ayacucho, Ancash, etc.) usan 3 vocales. Bolivia y Ecuador también tienen sus propias adaptaciones.